ChatGPT绘画:DALL-E3的不足之处

内容简介
本文介绍了ChatGPT里内置的AI绘图工具:DALL E3的优点和缺点。
Midjourney:AI绘图工具,使用人数最多。需要一定的技术,才能生成非常逼真的图像。 就像一个专业赛车,需要专业车手才能驾驭。
DALL E3: 几乎没有什么使用门槛,小白也能用它绘制满足日常需求的图片。 就像一辆大众汽车,普通人可以用它去接孩子、去商场购物等。
ChatGPT里的DALL E3还有一点:不是直接和AI绘图工具对话,而是经过一层:ChatGPT的提示词生成,命令最终才传到DALL E3里。 这个特点的好处:写提示词省心了;坏处:有一个中间人传话,容易曲解意思。
本文原作者: Thomas Smith,发布于medium。 叶赛文编译
正文
三年前,我有幸成为OpenAI早期的Beta测试者。在ChatGPT等模型正式发布前的几个月或几年里,我就已经在使用它们,那感觉令人兴奋不已。
虽然OpenAI早期的文本模型让我感到惊讶,但我依旧记得第一次使用DALL-E时的情景——OpenAI的第一代图像创作系统。
作为一名摄影师,仅需输入简单的提示就能获得实际图片的想法是开创性的。尽管这些图片宽度只有500像素,并且经常出现非常奇怪的内容(例如牛油果家具?),但它仍然给人一种科幻小说的感觉。
快进两年,如Midjourney这样的AI图像工具,已经能够制作出质量非常高的图片,甚至能够赢得摄影大赛。
因此,当OpenAI本周发布了备受期待的DALL-E3模型时,整个AI和摄影界都屏息以待,想看看DALL-E3能创造出什么新奇迹。
上周,我成为了首批获得DALL-E3使用权的用户之一。不幸的是,对于专业用户来说,新工具并没有像许多人希望的那样具有突破性或有趣。
然而,对某些用户而言,DALL-E3确实向前迈进了一大步。原因如下。
飞行中的盲目
就像ChatGPT Vision(ChatGPT识图功能,一个革命性的产品)一样,新的DALL-E3直接内置在ChatGPT界面中。你可以通过选择DALL-E3模型来访问它,就像你在不同的ChatGPT文本模型之间选择一样。
在对DALL-E3的初步演示中,OpenAI展示了你如何与ChatGPT对话,以便利用DALL-E3创建图像。
从外面看,DALL-E3似乎能理解它正在制作的图像的实际内容。
考虑到它与ChatGPT集成在一起,并且ChatGPT现在具有强大的视觉能力,看起来DALL-E3将是一个真正的多模态模型——一个基于对文本输入的完全理解来创建图像的模型。”
这本可以解锁一些惊人的能力。如果DALL-E3真正理解它正在创造的东西,你可以要求它生成一张特定车型的图片。
如果它在某个特性上出错了——比如加入了错误类型的扰流板或者变形的大灯——你只需简单写上类似“那个大灯看起来有点不对劲。你能把它做得更宽、更圆一些吗?”如果真正理解图片的话,ChatGPT和DALL-E3应该能够协作做出这些更改。
不幸的是,这根本不是 OpenAI 实际提供的。事实证明,DALL-E3 只是一个普通的 AI 图像生成系统,嫁接到开箱即用的 ChatGPT 上。
新系统实际上并不理解它创建的图像——它仅仅使用ChatGPT根据与用户的对话写出图像提示,然后将这些提示输入到DALL-E3中,这过程就像你将人工编写的提示词输入到Midjourney中一样。
DALL-E3的不足之处
SEO专家兼专业博主Anne Moss是首批发现这一点的人之一。
在一条推文中,她分享了 DALL-E3 难以创建逼真的图像,主要是因为用户交互和图像创建之间有一个中间步骤——自动编写提示。
如果ChatGPT正确理解了用户的意图,并为DALL-E3写出了一个好的提示,那么一切都可能进展顺利。但如果它理解错了——或者用户要求它做一些现有AI图像生成器做不到的事情——那么它就会失败。
以下是我自己测试的一些例子。
对于我的网站《湾区电讯报》(Bay Area Telegraph),我想制作一个关于BART火车系统乘客量的信息图表。我向ChatGPT提供了一些关于BART乘客量的数据,要求它制作一个信息图表。
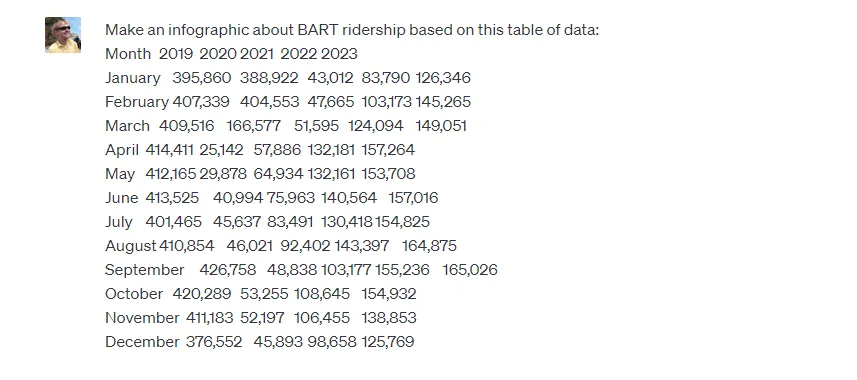
这是DALL-E3给我的结果:
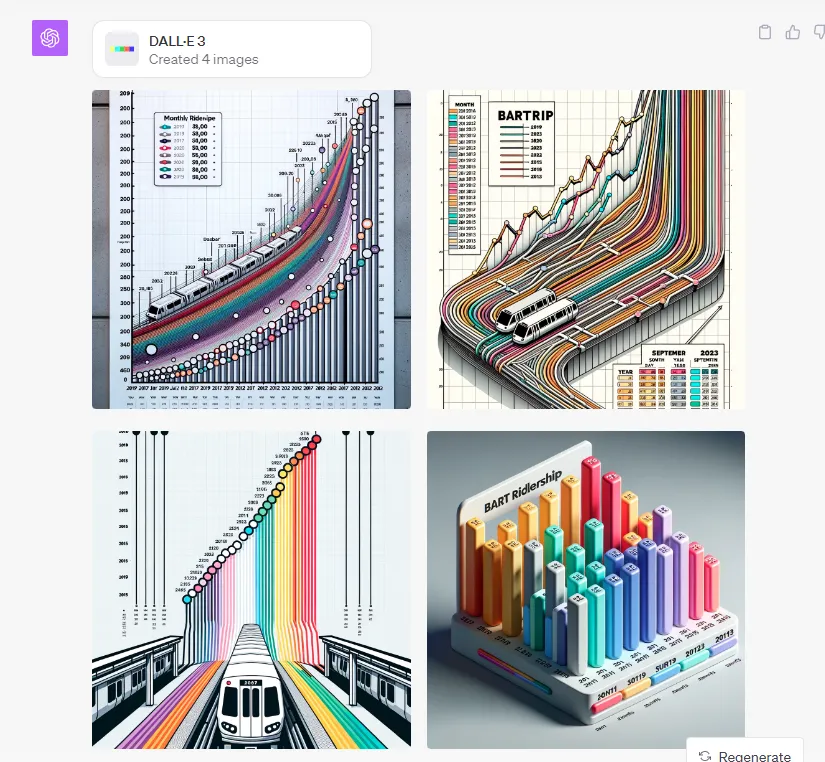
这些是很酷的图形。但它们甚至与我提供给系统的数据毫无关系。
为什么?当我要求ChatGPT根据我的数据制作信息图表时,它实际上并没有将那些数据交给DALL-E3。相反,它使用我的数据和指令编写了一个提示:
照片信息图表,展示了一张线图,可视化了2019年至2023年每月BART乘客量。横轴标有1月至12月,纵轴显示乘客数量,范围从0到500,000。每一年的线都有不同的颜色编码:2019年为蓝色,2020年为红色,2021年为绿色,2022年为紫色,2023年为橙色。每个月的数据点都用小圆圈清楚地标记出来。图表右侧附有一个图例,标明了每年的颜色。
然后将这个提示输入DALL-E3来创建图像。
这里存在几个问题:
- 提示实际上并不包含我的数据
- 提示本身没有意义。就算是人类设计师,给定这个提示也无法创建出一个好的信息图表
- 即便有了提示,最终的图像也没有准确的比例尺、图例或标题
同样地,我给ChatGPT喂了一篇我写的关于最近Google有用内容更新的博客文章,并要求它为这个故事创建一个插图。
再次,ChatGPT经历了编写提示给DALL-E3的中间步骤,因为它实际上不能直接与图像生成系统通信。
这是它创造的提示:
数字战场的插图:一边是贴有Reddit、Quora、Medium和YouTube标签的大巨人们,他们带着盾牌和旗帜向前冲,而在另一边,独立博主们则被描绘成拿着笔和记事本的较小身影,试图守住自己的地盘。头顶上,一个标有“谷歌有益内容更新”的云朵在战场上投下阴影。
这实际上对于人类设计师来说并不是一个糟糕的提示。但对于AI图像生成器来说,它过于复杂,无法理解。
不出所料,DALLE-3完全没能以任何有用或真实的方式解读它。

公平地说,Midjourney的表现也同样糟糕。

相比之下,这是我为实际用来插图的那个故事给Midjourney的基本提示词:
一个巨大的谷歌标志下降进入垃圾箱火焰之中的插图
这是AI生成器实际上能够理解的内容。它简单并且有一个清晰的视觉概念。它生成了一幅图像——经过一些手动编辑——完美契合了那个故事。

图像的自动变速箱
简而言之,DALL-E3及其伙伴ChatGPT之所以失败,是因为它们沟通不畅。ChatGPT写出了一个在概念上有意义的提示,但是一个生成性AI图像系统会觉得实际执行起来混乱。
相比之下,作为人类的我,既理解我试图在故事中传达的想法,也理解AI图像生成器的能力和局限性。
这些知识让我能够写出一个比DALL-E3的提示简单得多的提示,并且产生了一个视觉上引人入胜的图像。
DALL-E3目前的形态之所以表现不佳,是因为它需要中间步骤,即让ChatGPT编写提示。这使得用户失去了控制,大多数情况下会导致更糟糕的图像。
因此,DALL-E3有点像是带有自动变速箱的汽车。是的,有一个机器(自动变速箱)站在人和底层机制(汽车引擎)之间,使日常驾驶变得更容易。
你不需要考虑转速、引擎制动、即将到来的道路变化等。你只需要驾驶。
但是职业赛车手绝不会去驾驶一辆带有自动变速箱的车。
他们的技能和理解,使他们能够比任何机器更好地与汽车的引擎互动。通过汽车引擎的调节咆哮声和对道路或赛道的理解,他们可以准确地定时换挡,将其与转向、加速和无数其他因素同步。
最终,这些知识、技能和经验在比赛中给了他们巨大的竞争优势。
使用DALL-E3的感觉很相似。是的,有了系统的ChatGPT驱动的“自动变速”,你不需要亲自动手编写实际的提示。
但是,通过将这一责任交给机器,你就剥夺了自己直接与生成图像的底层机械互动的能力。
就像一位F1赛车手开普锐斯一样,你失去了利用人类技能和经验做出真正伟大事物的机会。
DALL-E3适合哪些人?
因此,对于专业插画家和创作者来说,DALL-E3 很难代表一个大的飞跃。当然,它不是我们都期待的那种能够无限制地生成信息图表、编辑图像的机器。
尽管如此,我预计DALLE-3将对生成性AI领域产生重大影响。
为什么?就像大多数司机不想学习如何驾驶手动档车一样,大多数ChatGPT用户也不想学习细腻且复杂的视觉提示工程技术。他们只是想快速描述一个基本图像,并在几秒钟后下载它。
有了其ChatGPT界面和自动提示,DALL-E3在这方面做得非常出色。
例如,假设你正在为你的行业贸易协会编写一份时事通讯。你被要求包括一个关于影响你行业的法律判决的部分,并且你需要一张简单的照片来说明它。
使用DALL-E3,你可以直接请求。例如,输入:
为我制作一张关于法律案件故事的插图
生成了这些图像:
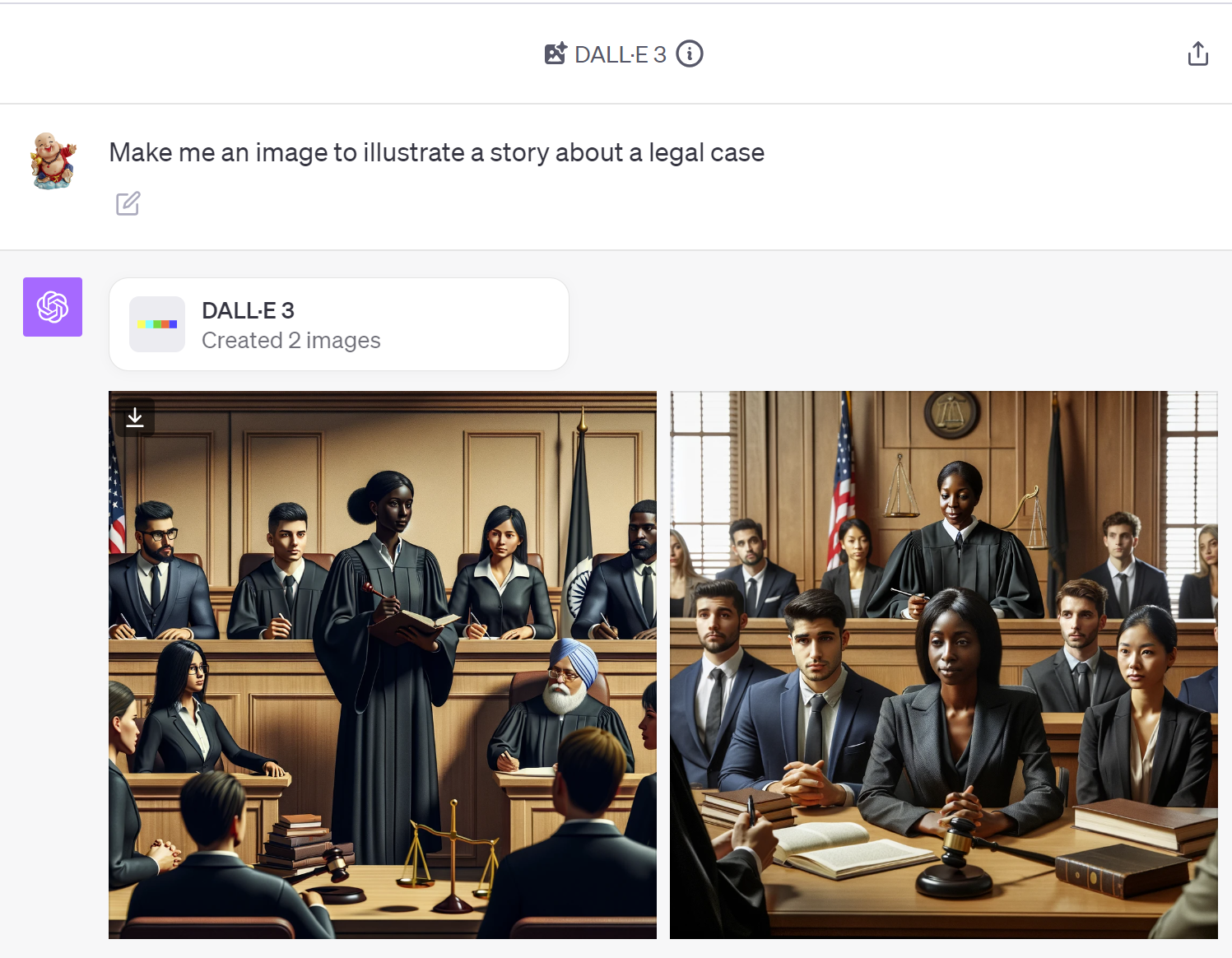
当然,它们不会赢得设计比赛。但它们是完全可用的库存插图,对于行业时事通讯来说完全可以。
相比之下,当你将同样的文本输入Midjourney时,你会得到这样的结果:

生成的图片非常棒!但它与你要报道的主题完全无关!
是的,像我这样的专家可以为Midjourney编写提示(“法庭上桌子上的木槌特写镜头,35mm照片,散布的蓝色背景,强烈的背景虚化效果,逼真的照片效果”),它生成的图像更适合我们假想的时事通讯:

但一个没有编写提示经验的普通人可以直接拿起DALL-E3,使用他们已经非常熟悉的界面,并在几秒钟内创建一个可用的AI图像,这是一个极其强大的新功能。
再说一次,赛车手可以比一位开本田奥德赛的足球爸爸更快更好地驾驶手动变速汽车,就像我这样的专家可以写出比新手更好的Midjourney提示词。
但大多数人并不是整天都在赛车!他们使用汽车是为了开车送孩子去学校或去好市多购物,而不是为了在纽博格林赛道上比赛。
同样,大多数ChatGPT用户不需要艺术上的完美 —— 他们需要的是基础AI图像,这些图像服务于简单的日常目的,不需要花几个月的时间来训练编写提示。
而DALL-E3在制作这些方面确实很擅长。
DALL-E3的未来
根据我迄今为止测试DALLE-3的所见,可以肯定地说,许多专业创作者目前可以坚持使用手动提示和Midjourney。
但随着时间的推移,这种情况可能会改变。随着OpenAI向全模态系统过渡,他们很可能将ChatGPT视觉和DALL-E3整合在一起。一旦发生这种情况,系统可能真正实现专业创作者所期待的一些功能 —— 例如,从数据表中创建信息图表的能力。
在那之前,DALL-E3将主要作为向日常用户介绍AI图像生成器强大功能的工具。从这个意义上说,它可能仍然会非常受欢迎。
记得OpenAI的大型语言模型GPT-3已经存在了18个月,之后简单易用的ChatGPT界面使其成为普通人可用的工具。将GPT模型的强大功能与聊天机器人的简单界面结合在一起,产生了历史上增长最快的产品。
借用我自己的背景,像我这样的专业摄影师可以使用价值 5,000 美元的无反光镜相机在拍摄过程中进行完全的创意控制,捕捉到与我们的创意愿景完美匹配的图像。
但大多数人不会用专业的无反光镜相机拍照。他们用 iPhone 拍摄快照。
界面、易用性和简单性很重要。正是这些因素可能使DALL-E3比许多专业人士预期的影响更大。
广告
一个集美剧、音乐和AI工具为一体的服务商:
优惠码: 2018 ,有九折优惠


发表评论