我如何夺得新加坡首届GPT-4提示工程大赛冠军(第四部分)
内容简介:
在2023年11月举行的新加坡首届GPT-4提示工程大赛中,张席拉(Sheila Teo)获得了冠军,并在这篇文章中,阐述了个人对提示词的心得体会。
她的文章里,写了4种提示词方法。
原文较长,拆分为了4部分。本文是第四部分——AI的高级用法:使用AI进行数据分析。
虽然数据分析很多人用不上,但是文末的4个技巧:拆分任务、引用变量、把命令和数据分开输入,很实用。
原作者:张席拉(Sheila Teo),发布于medium。叶赛文编译。 原文链接: https://towardsdatascience.com/how-i-won-singapores-gpt-4-prompt-engineering-competition-34c195a93d41

正文
文章目录
4. [🔴] 不使用插件或代码,仅用LLMs分析数据集
你可能听说过OpenAI为GPT-4的ChatGPT提供的高级数据分析插件,这是付费账户的特权。这个插件允许用户上传数据集并直接在ChatGPT上运行代码,实现精确的数据分析。
但你可能不知道,即使没有这样的插件,我们也能很好地利用LLMs来分析数据集。首先,我们需要了解纯粹利用LLMs分析数据集时的优势和局限。
LLMs并不擅长的数据集分析类型
如你所知,LLMs在执行精确数学计算方面有限,不适合需要精确量化分析的任务,比如:
- 描述性统计:通过平均值或方差等量化手段总结数值列。
- 相关性分析:计算列之间的精确相关系数。
- 统计分析:例如,进行假设测试以确定数据点组之间是否存在统计学显著差异。
- 机器学习:在数据集上进行预测建模,如使用线性回归、梯度提升树或神经网络。
这些定量任务是OpenAI高级数据分析插件存在的原因,以便用编程语言在数据集上执行这些任务的代码。
那么,为什么有人想仅用LLMs而不用这些插件来分析数据集呢?
LLMs擅长的数据集分析类型
LLMs非常擅长识别模式和趋势。这种能力源于它们对广泛和大量数据的深入训练,使它们能够识别可能不那么明显的复杂模式。
这使得LLMs非常适合基于模式发现的任务,例如:
- 异常检测:识别基于一个或多个列值偏离常态的异常数据点。
- 聚类:根据列中的相似特征将数据点分组。
- 跨列关系:识别跨列的联合趋势。
- 文本分析(针对文本列):基于主题或情感进行分类。
- 趋势分析(针对具有时间维度的数据集):识别随时间变化的列中的模式、季节性变化或趋势。
对于这类基于模式的任务,仅用LLMs可能实际上会比使用代码更快地得到更好的结果!让我们用一个实例来完整展示这一点。
仅用LLMs分析Kaggle数据集
我们将使用Kaggle上流行的、为客户个性分析而精心策划的真实世界数据集,其中一家公司希望对其客户基础进行细分,以更好地理解其客户。
为了便于验证LLM的分析,我们将这个数据集缩减到50行,并仅保留最相关的列。之后,用于分析的数据集如下所示,每行代表一个客户,列显示了客户信息:

假设你在公司的市场营销团队工作。你的任务是利用这个客户信息数据集来指导市场营销工作。这是一个两步骤的任务:
首先,使用数据集生成有意义的客户群体。
接下来,为每个群体生成最佳的市场营销策略。这是一个实际的商业问题,LLMs的模式发现能力(对于第一步)可以真正大放异彩。
让我们使用以下4种提示工程技巧(稍后详细介绍)来为这个任务制定提示:
- 将复杂任务分解成简单步骤
- 引用每个步骤的中间产出
- 格式化LLM的回应
- 将指令与数据集分开
系统提示: 我希望你扮演数据科学家来分析数据集。不要编造数据集中不存在的信息。对于我要求的每个分析,请向我提供确切且明确的答案,不要提供代码或指示在其他平台上进行分析。
提示: #上下文-context#
我卖葡萄酒。我有一个关于我的客户的数据集:[出生年份,婚姻状况,收入,孩子数量,上次购买距今的天数,花费金额]。
#############
#目标-objective#
我希望你使用数据集将我的客户分组,然后给我一些关于如何针对每个组进行营销的想法。使用这个逐步过程,不要使用代码:
- CLUSTERS:使用数据集的列对数据集的行进行聚类,这样同一聚类中的客户具有相似的列值,而不同聚类中的客户具有明显不同的列值。确保每一行只属于1个聚类。 对于每个找到的聚类,
- CLUSTER_INFORMATION:根据数据集的列描述聚类。
- CLUSTER_NAME:解释[CLUSTER_INFORMATION]以获得此聚类中的客户组的简称。
- MARKETING_IDEAS:生成针对这个客户组的产品营销想法。
- RATIONALE:解释为什么[MARKETING_IDEAS]对这个客户组是相关和有效的。
#############
# 风格-style #
商业分析报告
#############
# 语气 -tone#
专业,技术性
#############
# 受众-audience #
我的商业伙伴。说服他们你的营销策略是经过深思熟虑的,并完全有数据支持。
#############
# 回应-response:MARKDOWN报告 #
<对于[CLUSTERS]中的每个聚类>
— 客户群体:[CLUSTER_NAME]
— 概况:[CLUSTER_INFORMATION]
— 营销想法:[MARKETING_IDEAS]
— 理由:[RATIONALE]
<附件>
提供属于每个聚类的行号列表,以支持你的分析。使用这些表头:[[CLUSTER_NAME], 行号列表]。
#############
# 开始分析 #
如果你理解,请向我索要我的数据集。
GPT-4的回应如下,我们随后将数据集以CSV字符串的形式传递给它。

接着,GPT-4按照我们要求的markdown报告格式回复了它的分析:



验证LLM的分析
为了简洁起见,我们将验证LLM生成的两个客户群体——假设是“年轻家庭”和“挑剔的爱好者”。
年轻家庭
- LLM合成的概况:1980年后出生,已婚或同居,中等到低收入,有孩子,频繁小额购买。
- LLM将这些行分入该组:3, 4, 7, 10, 16, 20
- 深入数据集,这些行的完整数据是:
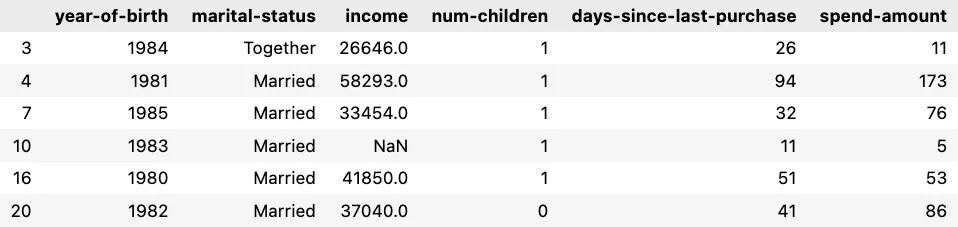
这与LLM识别的概况完全一致。它甚至能够在我们事先没有预处理的情况下对带有空值的行进行聚类!
挑剔的爱好者
- LLM合成的概况:年龄范围广,任何婚姻状况,高收入,孩子状况多样,购买花费高。
- LLM将这些行分入该组:2, 5, 18, 29, 34, 36
- 深入数据集,这些行的完整数据是:

这再次与LLM识别的概况非常吻合!
这个示例展示了LLMs在模式发现、解释和提炼多维数据集为有意义的洞察力方面的能力,同时确保其分析深深植根于数据集的事实真相。
如果我们使用ChatGPT的高级数据分析插件会怎样?
为了完整性,我尝试了同样的任务,使用相同的提示,但要求ChatGPT使用代码执行分析,这激活了它的高级数据分析插件。该插件的想法是使用诸如K-Means之类的聚类算法直接在数据集上运行代码以获得每个客户组,然后综合每个聚类的概况以提供营销策略。
然而,多次尝试结果显示以下错误消息,尽管数据集仅有50行,却没有输出:


对于现在的高级数据分析插件来说,执行数据集上的简单任务似乎很容易,例如计算描述性统计或创建图表,但更高级的任务可能有时会因计算限制或其他原因导致错误和无输出。
那么……什么时候使用LLMs分析数据集?
答案是:这取决于分析的类型。
对于需要精确数学计算或复杂的基于规则的处理的任务,传统编程方法仍然更优越。
对于基于模式识别的任务,使用传统编程和算法方法执行可能会具有挑战性或更耗时。然而,LLMs在这些任务上表现出色,并且甚至可以提供额外的输出,例如附件来支持其分析,以及用markdown格式的完整分析报告。
最终,使用LLMs的决定取决于手头任务的性质,平衡LLMs在模式识别方面的优势与传统编程技术提供的精确度和特异性。
现在回到提示工程!
在本节结束之前,让我们回到用于生成这个数据集分析的提示,并分解使用的关键提示工程技术:
提示词:
# 上下文-context #
我卖葡萄酒。我有一个关于我的客户的数据集:[出生年份,婚姻状况,收入,孩子数量,上次购买距今的天数,花费金额]。
#############
# 目标-objective # 我希望你使用数据集将我的客户分组,然后给我一些关于如何针对每个组进行营销的想法。使用这个逐步过程,不要使用代码:
- CLUSTERS:使用数据集的列对数据集的行进行聚类,这样同一聚类中的客户具有相似的列值,而不同聚类中的客户具有明显不同的列值。确保每一行只属于1个聚类。
对于每个找到的聚类, 2. CLUSTER_INFORMATION:根据数据集的列描述聚类。 3. CLUSTER_NAME:解释[CLUSTER_INFORMATION]以获得此聚类中的客户组的简称。 4. MARKETING_IDEAS:生成针对这个客户组的产品营销想法。 5. RATIONALE:解释为什么[MARKETING_IDEAS]对这个客户组是相关和有效的。
#############
# 风格-style # 商业分析报告
#############
# 语气 #
专业,技术性
#############
# 受众
我的商业伙伴。说服他们你的营销策略是经过深思熟虑的,并完全有数据支持。
#############
# 回应:MARKDOWN报告
<对于[CLUSTERS]中的每个聚类>
— 客户群体:[CLUSTER_NAME]
— 概况:[CLUSTER_INFORMATION]
— 营销想法:[MARKETING_IDEAS]
— 理由:[RATIONALE]
<附件> 提供属于每个聚类的行号列表,以支持你的分析。使用这些表头:[[CLUSTER_NAME], 行号列表]。
#############
# 开始分析
如果你理解,请向我索要我的数据集。
技巧1:将复杂任务分解为简单步骤
LLMs非常擅长执行简单任务,但在处理复杂任务时就没那么在行了。
因此,对于像这样的复杂任务,重要的是将任务分解成简单的逐步指令,让LLM能够跟随。这个想法是给LLM你自己执行任务时会采取的步骤。
在这个示例中,步骤是这样给出的:
使用这个逐步过程,不要使用代码:
- CLUSTERS:使用数据集的列对数据集的行进行聚类,这样同一聚类中的客户具有相似的列值,而不同聚类中的客户具有明显不同的列值。确保每一行只属于1个聚类。
对于每个找到的聚类,
- CLUSTER_INFORMATION:根据数据集的列描述聚类。
- CLUSTER_NAME:解释[CLUSTER_INFORMATION]以获得此聚类中的客户组的简称。
- MARKETING_IDEAS:生成针对这个客户组的产品营销想法。
- RATIONALE:解释为什么[MARKETING_IDEAS]对这个客户组是相关和有效的。
而不是简单地将整体任务作为“将客户分组,然后给出如何向每个组营销的想法”交给LLM。
通过逐步指令,LLMs显著更有可能提供正确的结果。
技巧2:引用每个步骤的中间输出 (intermediate outputs)
在向LLM提供逐步过程时,我们给每个步骤的中间产出都起了一个大写的变量名称(VARIABLE_NAME),即CLUSTERS, CLUSTER_INFORMATION, CLUSTER_NAME, MARKETING_IDEAS和RATIONALE。
使用大写来区分这些变量名和给出的指令主体。这些中间输出稍后可以使用方括号[VARIABLE_NAME]引用。
技巧3:格式化LLM的响应
在这里,我们要求markdown报告格式,这使LLM的响应更美观。再次使用中间产出的变量名来指定报告的结构。
# 回应:MARKDOWN报告
<对于[CLUSTERS]中的每个聚类>
— 客户群体:[CLUSTER_NAME]
— 概况:[CLUSTER_INFORMATION]
— 营销想法:[MARKETING_IDEAS]
— 理由:[RATIONALE]
<附件>
提供属于每个聚类的行号列表,以支持你的分析。使用这些表头:[[CLUSTER_NAME], 行号列表]。
事实上,你甚至可以随后要求ChatGPT提供报告的可下载文件,让你能够在撰写最终报告时使用其响应。
技巧4:将任务指令与数据集分开
你会注意到,在我们的第一个提示中,我们从未将数据集提供给LLM。相反,提示仅给出了数据集分析的任务指令,并在底部添加了以下内容:
# 开始分析 #
如果你理解,请向我索要我的数据集。
ChatGPT随后回应说它理解了,我们在下一个提示中以CSV字符串的形式传递了数据集:

但为什么要将指令与数据集分开呢?
简单的答案是,LLMs有其上下文窗口的限制,或者说是它们在一个提示中可以作为输入的标记数量限制。一个将指令和数据结合的长提示可能会超过这个限制,导致截断和信息丢失。
更复杂的答案是,将指令和数据集分开有助于LLM清晰地理解每一个,降低遗漏信息的可能性。
你可能经历过这样的情况,当LLM在较长的提示中“不小心忘记”了你给出的某个指令——例如,如果你要求100字的回应,而LLM给你返回了一个更长的段落。
通过先接收指令,然后是指令所针对的数据集,LLM可以先消化它应该做什么,然后在下一个提供的数据集上执行它。
不过请注意,在使用基于对话的大型语言模型(chat LLMs,如ChatGPT)时,可以将执行任务的指令和数据集分开提供。这是因为这类模型具备对话记忆功能,能够记住之前的交互内容。因此,你可以先提供任务的指令,等模型确认理解后,再在后续的交互中提供数据集。
相比之下,完成型大型语言模型(completion LLMs)没有对话记忆功能。这类模型每次响应都是基于单次输入,它们不会记住之前的交互内容。因此,你不能分开提供指令和数据集,因为模型无法将前一次的指令记忆应用到后续的交互中。
结束语
在本文结束前,我想分享一些个人的反思。
首先,衷心感谢新加坡GovTech组织了这样一场精彩的比赛。

其次,向我那些非凡的竞争对手们致以热烈的欢呼,每个人都带来了特别的东西,使这场比赛既充实又具有挑战性!我永远不会忘记决赛,我们在舞台上竞争,现场观众为我们加油——这是一次我将永远怀念的经历。
对我来说,这不仅仅是一场比赛;这是才华、创造力和学习精神的庆祝。我非常兴奋地期待着接下来会发生什么!
广告
一个集美剧、音乐和AI工具为一体的服务商:
优惠码: ysw ,有九折优惠

发表评论